普林斯顿算法(1.0)背包、队列和栈
许多基础数据类型都和对象的集合有关。具体来说,数据类型的值就是一组对象的集合,所有的操作都是关于添加、删除或是访问集合中的对象。
本节介绍三种数据类型:背包(Bag)、队列(Queue)和栈(Stack),它们的不同之处在于删除或访问对象的顺序不同。同时还介绍了三种数据类型的数组实现及简单应用,在下一篇中介绍链表及这三种数据类型的链表实现。
数据类型简介
背包
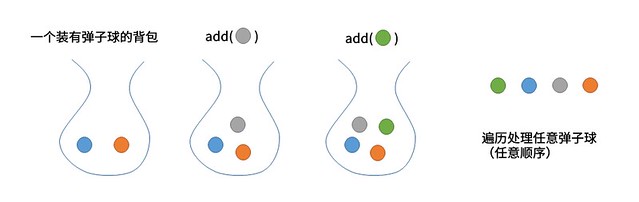
背包(Bag)是一种不支持从中删除元素的集合数据类型——它的目的就是帮助用例收集元素并迭代遍历所有收集到的元素。迭代遍历的顺序不确定且与用例无关。背包的概念可以借助以下图示理解。
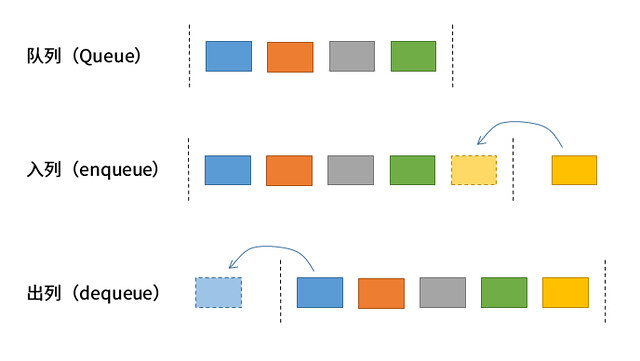
先进先出队列
先进先出队列(Queue,简称队列)是一种基于先进先出(FIFO: First In First Out)策略的集合类型。队列的一个十分常见的例子就是在排队的人。当用例使用遍历访问队列中的元素时,元素的处理顺序就是它们被添加到队列中的顺序。在应用程序中使用队列的主要原因是在用集合保存元素时同时保存它们的相对顺序:使它们入列顺序和出列顺序相同。下图是队列的操作示例。
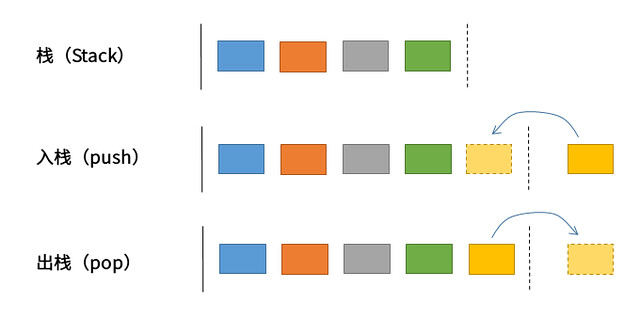
下压栈
下压栈(Stack,简称栈)是一种基于后进先出(LIFO: Last In First Out)策略的集合类型。在生活中堆成一叠的文件就可以当作一个下压栈,新文件放到最上面,而取出文件阅读时也从最上面开始阅读。这样处理的好处是总能够得到未被处理的文件中最新的一份,坏处是如果不把栈清空,较早的文件可能永远不会被处理。当用例遍历访问栈中的元素时,元素的处理顺序与它们被压入栈中的顺序正好相反。在应用程序中使用栈的一个典型原因是在用集合保存元素的同时颠倒它们的相对顺序。下图是栈的操作示例。
数组实现
定容数组
一种实现Bag,Queue及Stack的简单而经典的方法就是使用数组来保存集合中的数据。Java中的数组在创建时需要指定大小,之后其大小是无法改变的。以下为用定容数组实现的定容字符串栈。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21public class FixedCapacityStack<Item>
{
private Item[] a;
private int N;
public FixedCapacityStack(int cap)
{
/*
在Java中创建泛型数组是不允许的,不能使用 a = new Item[cap]。
因此使用类型转换来创建一个泛型的数组,但编译器会给出警告。
*/
a = (Item[]) new Object[cap];
}
public boolean isEmpty()
{ return N == 0; }
public int size()
{ return N; }
public void push(Item item)
{ a[N++] = item; }
public Item pop()
{ return a [--N]; }
}
调整数组大小
由于Java中数组的大小无法动态改变,因此集合使用的空间只能是这个最大容量的一部分。大容量的用例在集合几乎为空时会浪费大量的内存。另一方面,当集合变得比数组更大时用例可能会溢出(Overflow)。如果动态的调整数组的大小就可以避免以上的问题,实现的方法就是将集合在需要时移动到一个大小不同的数组中去。 但是在两个数组中整体的移动集合可能会耗费大量的资源,每次移动集合就需要对集合中的每个元素执行一次读取和写入操作,因此频繁的移动集合是很得不偿失的。同时,如果不经常移动集合,当集合远小于数组大小时,会浪费大量的内存。
一个较好的策略是:
当集合大小增加至数组大小时,将集合移动到另一个原数组两倍大的数组中;当集合大小减小至小于数组的四分之一时,将集合移动到另一个原数组一半大的数组中。
以下是一个动态调整数组大小的栈
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29public class ResizingArrayStack<Item>
{
private Item[] a = (Item[]) new Object[1];
private int N = 0;
public boolean isEmpty() { return N == 0; }
public int size() { return N; }
private void resize(int max)
{
Item[] temp = (Item[]) new Object[max];
for (int i = 0; i < N; i++)
temp[i] = a[i];
a = temp;
}
public void push(Item item)
{
if (N == a.length) resize(2 * a.length);
a[N++] = item;
}
public Item pop()
{
Item item = a[--N];
a[N] = null; //避免对象游离,提示系统垃圾回收不再使用的对象
if (N > 0 && N == a.length / 4) resize(a.length/2);
return item;
}
}
应用
算术表达式求值
栈的一个经典用例是计算算术表达式的值,例如:
( 1 + ( ( 2 + 3 ) * ( 4 + 5 ) ) )
为了简单起见,这里没有省略多余的括号,即只用括号来表示运算的优先级。 E.W.Dijkstra在20世纪60年代发明了一个非常简单的算法来计算算术表达式的值:
表达式由括号、运算符和操作数(数字)组成。用两个栈(一个保存运算符,一个保存操作数)保存数据,并根据以下4中情况从左至右逐个将这些实体送入栈处理:
- 将操作数压入操作数栈;
- 将运算符压入运算符栈;
- 忽略左括号;
- 在遇到右括号时,弹出一个运算符,弹出所需数量的操作数,并将运算符和操作数的运算结果压入操作数栈。
处理完最后一个右括号后,操作数栈上只会有一个值,即表达式的值。
用图示来解释以上算术表达式的运算过程:

算法示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35import edu.princeton.cs.algs4.StdIn;
import edu.princeton.cs.algs4.StdOut;
import edu.princeton.cs.algs4.Stack;
public class Evaluate
{
public static void main(String[] args)
{
Stack<String> ops = new Stack<String>();
Stack<Double> vals = new Stack<Double>();
while (!StdIn.isEmpty())
{
String s = StdIn.readString();
if (s.equals("(")) ;
else if (s.equals("+")) ops.push(s);
else if (s.equals("-")) ops.push(s);
else if (s.equals("*")) ops.push(s);
else if (s.equals("/")) ops.push(s);
else if (s.equals("sqrt")) ops.push(s);
else if (s.equals(")"))
{
String op = ops.pop();
double v = vals.pop();
if (op.equals("+")) v = vals.pop() + v;
else if (op.equals("-")) v = vals.pop() - v;
else if (op.equals("*")) v = vals.pop() * v;
else if (op.equals("/")) v = vals.pop() / v;
else if (op.equals("sqrt")) v = Math.sqrt(v);
vals.push(v);
}
else vals.push(Double.parseDouble(s));
}
StdOut.println(vals.pop());
}
}