普林斯顿算法(1.3)并查集(union-find算法)
假设在互联网中有两台计算机需要互相通信,那么该怎么确定它们之间是否已经连接起来还是需要架设新的线路连接这两台计算机。这就是动态连通性问题。动态连通性问题在日常生活中十分常见,比如上文所说的通信网络中的连通性问题,比如物理化学中的渗流问题。通过并查集这种数据结构及union-find算法可以解决动态连通性问题。
动态连通性问题
概念
给出一系列的对象时,让其支持以下的两个操作:
- 判断两个对象是否相连
- 使两个对象相连
这里以整数代表对象,有0-9共十个整数,当给出一个整数对(a, b)时表示将整数a和b相连(如果a、b不相连)。如下图所示:
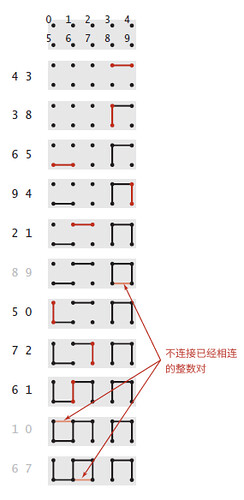
随着整数对的输入,十个整数的连通性会发生变化,这就是动态连通性问题。
在动态连通性问题中,我们假设“相连”是一种等价关系,也就意味着它具有:
- 自反性:p和p是相连的
- 对称性:如果p和q是相连的,那么q和p也是相连的
- 传递性:如果p和q是相连的且q和r是相连的,那么p和r是相连的。
在所有给出的对象中,所有相连的一组对象称为连通分量(Connected component)。如上图中最后一行的(0, 1, 2, 5, 6, 7)和(3, 4, 8, 9)分别为两个连通分量。
应用
- 计算机网络:判断网络中的计算机是否可以通过已存在的连接直接通信;
- 社交网络中的朋友关系:将朋友关系当作相连,判断两个人之间的朋友关系;
- 计算机芯片中晶体管的连接问题:判断芯片中晶体管是否相连;
- 变量名的等价性:某些编程语言(如FORTRAN)中允许声明两个等价的变量名,判断两个给定的变量名是否等价;
- 数学集合中的元素:元素可能属于不同的集合,将元素“相连”表示将两个元素所属的集合合并成一个集合。
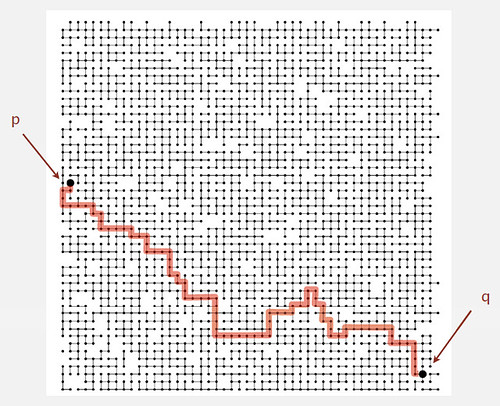
如在下图所示的所有连接中判断p和q点之间是否相连。
设计算法
在为动态连通性问题设计算法之前要精确的定义问题,动态连通性问题只要求给出两个点是否相连,并不要求给出具体的连接路径,至于得到连接路径的问题,可以通过深度优先搜索(DFS)算法来解决。
在该算法中,要实现以下操作:
- Find:给出的对象p属于哪个分量;
- Connected:对象p和q是否相连;
- Union:连接对象p和q并将它们所属的分量合并为一个分量。
那么判断两个对象是否相连的最直观简单的方法就是判断它们所属的分量是否相同。所对应的union-find算法API如下:
| public class UF | ||
|---|---|---|
| UF(int N) | 以整数标识(0到N-1)初始化N个触点 | |
| void | union(int p, int q) | 在p和q之间添加一条连接 |
| int | find(int p) | 返回p所在分量的标识符 |
| boolean | connected(int p , int q) | 判断p和q是否相连 |
| int | count() | 所有连通分量的数量 |
在这份API中,用整数表示一个对象(借用网络中的术语,将对象称为触点),那么N个触点就用0到N-1的整数标识。用一个以触点为索引的数组作为基本的数据结构来表示所有的分量,使用分量中的某个触点的名称作为分量的标识符。初始化时触点之间都不相连,因此有N个分量,每个触点构成一个只含有自己的分量。一份初始的代码实现如下:
1 | public class UF |
下面将分别介绍不同的find()和union()方法的实现。
快速查找
既然用分量标识符代表一个分量,那么直接使同一分量中的所有触点的分量标识符相同即可,在判断两个触点的连通情况时只需比较其对应的分量标识符是否相同,即 id[p] == id[q]。那么在实现union()方法时,首先判断p和q是否同属一个分量,如果不是,则需要合并两者所代表的分量。根据同一分量中所有触点的分量标识符相同的原则,遍历整个数组,将所有与id[p]相等的元素值变为id[q]。这样的实现称为quick-find(快速查找)算法。
实现
1 | public int find(int p) { return id[p]; } |
算法分析
在quick-find算法中,find()操作的速度很快,但是在union()操作中,每一对处于不同分量的输入都需要遍历整个id[]数组。每个方法执行中访问数组的次数如下表所示:
| 方法 | 内部调用 | 访问数组次数 | 合计 |
|---|---|---|---|
| find() | 1 | 1 | |
| union()* | 判断是否相连 | 2 | N+3 ~ 2N+1 |
| 检查所有元素 | N | ||
| 改变元素 | 1 ~ N-1 |
*假设两个分量需合并
那么假设使用quick-find算法来解决动态连通性问题并且最后只得到一个连通分量时,至少需要调用N-1次union()方法,即至少要(N+3)(N-1) ~ N^2次访问数组。quick-find算法的复杂度是平方级别的,当数组较大时,运行的效率就较低了。
快速合并
在quick-find算法中,find()操作速度很快,而union()操作当需要合并分量时要遍历整个数组因而效率较低。在合并分量时,需要关注的并不是所有的触点,只是与元素p同属一个分量的触点才需要被访问,因此,将同一分量中的触点组织结合起来,当需要修改时直接访问该分量中的触点可以减少无关触点的访问。
同样是以触点为索引的id[]数组,但其中保存的值不再是相同的分量标识符,而是同一分量中另一个触点(可能为自己)的名称。当实现find()方法时,从给定的触点开始,再由这个触点链接到第三个触点,直到根触点——链接指向自己的触点,那么这个根触点就代表了这个分量。当判断两个触点是否相连时,沿着各自的链接得到根触点后比较根触点是否相同即可。
在实现union()方法时,为了保证合并后的两个分量中的所有触点的根触点相同,直接将其中一个分量的根触点链接到另一个分量的根触点上就可以快速的合并两个分量。因此这个算法叫做quick-union(快速合并)算法。
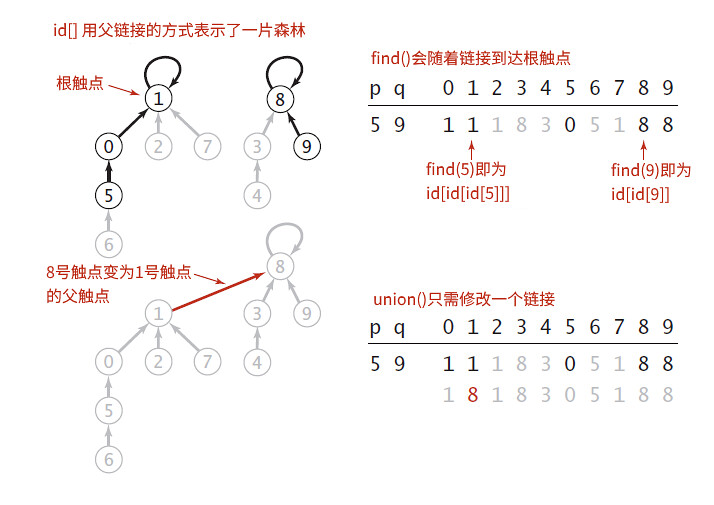
从上图的quick-union算法示意图可以看出,quick-union算法中采用了树结构来取代quick-find中使用的数组来组织元素,实现高效的元素查找与修改。
实现
1 | public int find(int p) |
算法分析
quick-union算法看起来比quick-union算法更快,因为它不需要在每次合并分量时遍历整个数组。但是quick-union算法的性能依赖输入的特点。在最好的情况下,find()方法只需要访问数组一次就可以得到根触点,此时的算法复杂度是线性级别的。但是想象一下这种情况:输入的整数对是完全有序的0-1,0-2,0-3等,N-1对之后N个触点将全部处相同的分量之中(如下图所示)。此时find()操作仍然需要2N+1次数组访问,此时的算法复杂度为平方级别。
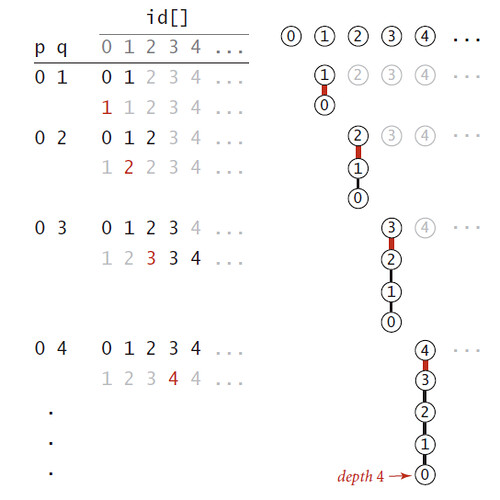
因此,quick-union算法可以看做是对quick-find算法的一种改良,它解决了quick-find算法中union()操作总是线性级别的问题。但quick-union算法仍然存在问题,它不是在所有输入情况下都比quick-find算法快。在下一篇文章中将介绍对quick-union算法的优化,以达到更好的性能。