普林斯顿算法(1.4)quick-union算法的优化
在动态连通性问题中,quick-union算法改进了quick-find算法中union()方法的执行速度,但是并不能在所有输入情况下都提升执行速度。以下来介绍对于quick-union算法的一些优化。
加权quick-union算法
在quick-union算法中,使用了树这种数据结构来组织数据,但是在某些输入情况下,树的高度会变得太高,导致从某些触点链接到根触点的中间过程(find()方法执行过程)太多。查看quick-union算法的实现,树高度的增长来自于union()方法中合并两个分量的过程,即以下代码:
1 | id[pRoot] = qRoot; |
可以看到这行代码直接将p触点所在的分量链接到了q触点所在分量的根触点上,并没有进行任何的比较判断(可以说这个链接的过程中选择链接方向是随意的)。这样当每次的输入都是p触点所在分量(树)较高时,会导致树的高度快速增加。那么解决方案就较为简单了,在链接两个分量之前,对两个分量进行比较,保证将较小的树链接到较大的树上。这样,树会倾向于横向的长大,而不是长高。
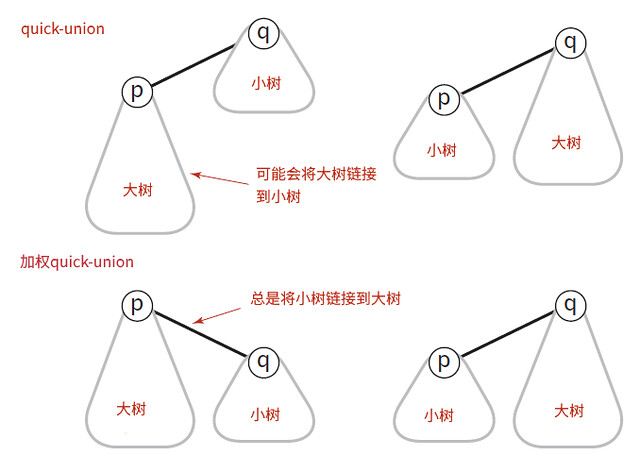
为了随时获得每个分量所在树的大小,需要添加一个数组(sz)来记录每个分量树中触点的个数。初始化时,每个触点都是独立的一个分量,每个分量的大小都是1,当合并两个分量时,首先获得分量根触点及根触点所代表的分量大小,比较之后将较小的分量链接到较大的分量,最后更新合成后分量(较大分量)根触点所代表的分量大小。
实现
1 | public class WeightedQuickUnionUF |
算法分析

通过两种算法对比图可以看出,加权quick-union算法最后得到的树要“扁平”的多,树的高度大幅减小,在执行find()方法时也更有效率。加权quick-union算法构造的森林中的任意节点的深度最多为lgN,比quick-union算法中的最大深度N要小得多。在处理有N个触点M条连接时加权quick-union算法最多访问数组cMlgN次,其中c为常数;而quick-find算法需要访问数组MN次。加权quick-union算法能够保证在合理的时间范围内解决实际中的大规模动态连通性问题。
最优算法
通过上面加权quick-union算法的分析,很容易发现,对于最优化的quick-union算法而言,得到的应该是一颗十分扁平的树,最为极端的情况就是在分量中所有的触点都直接链接到根触点上,即进行路径压缩。实现路径压缩很简单,在加权quick-union算法的find*()方法中,将在寻找根触点过程中遇到的所有触点都直接链接到根触点上。
实现
1 | private int find(int p) |
算法分析
路径压缩的加权quick-union算法得到的是几乎完全扁平的树。但是从代码中很容易发现,在find()方法中找到根触点后要对遇到的所有触点再次进行读取操作,虽然路径被压缩了,但是对数组的读取并不能完全降至1次。因此虽然路径压缩的加权quick-union算法是最优的算法,但并非所有操作都能在常数时间内完成。
除了这种极端的路径压缩方法,也有实现更为简单但是压缩效率不那么高的路径压缩方法,比如:将遇到的触点的父节点指向该触点的父触点的父触点(爷爷触点),相当于在寻找根触点的同时,对路径进行了压缩。其实现十分简单,只需要在find()方法中添加一行代码。当然在一些输入情况下,树的深度会远超过2,所以这种简单的路径压缩方法并没有上面所说的算法高效。
1
2
3
4
5
6
7
8
9
10private int find(int p)
{
while(p != id[p])
{
// 将p节点链接到其的爷爷触点
id[p] = id[id[p]];
p = id[p];
}
return p;
}
总结
在union-find算法中路径压缩的加权quick-union算法是最优的算法,但并非所有操作都能在常数时间内完成。且不存在其他算法能够保证union-find算法的所有操作在均摊后都是常数级别的。
各种union-find算法的性能特点如下:
| 算法 | 构造函数* | union()* | find()* |
|---|---|---|---|
| quick-find算法 | N | N | 1 |
| quick-union算法 | N | 树高度 | 树高度 |
| 加权quick-union算法 | N | lgN | lgN |
| 路径压缩的加权quick-union算法 | N | 接近1但未达到1(均摊成本) | 接近1但未达到1(均摊成本) |
| 理想情况 | N | 1 | 1 |
*存在N个触点时成本的增长数量级(最坏情况下)